Feb 20, 2024
Introduction
Welcome to the second article of Understanding the Essentials. Today, we are learning about two famous machine learning algorithms that are often confused due to the similarity in their names (KNN and K means). The K in their names are not the same; in fact, both algorithms serve different purposes in different scenarios. Before I dive into how the algorithms work, we need to understand what supervised and unsupervised learning techniques are, as Knn is a supervised learning technique and K means is an unsupervised learning technique. If you already know how Supervised and Unsupervised learning works, please skip to the KNN part.
Supervised Learning
This is when a model gets trained on a “Labelled dataset”. We fit the model with the data's inputs (features) and outputs (labels). In the end, we expect our model to predict outputs for a new set of input data. To make this clearer, here is an image.
Source: Metehan Kozan
There are two types of supervised learning techniques:
Classification: models classify our outputs into certain categories. If the number of categories is only two, then it is called a binary classification. For a greater number of categories, it is called multi-class classification. Some examples could be:
- Classify student grades for assignments into A, B, and C.
- Classify if a person is a loan defaulter or not.Regression: Here, the results have continuous values. If you want to learn about common regression techniques, you can read this article. Some examples are:
- Predicting Stock prices.
- Predicting Real estate prices.
Unsupervised Learning
Unsupervised learning, on the other hand, involves training data without any labeled responses. The algorithm tries to find patterns in the data without being told what to do or what outputs to compare with.
This image should help.
Source: Metehan Kozan
As you can see, we don’t tell the model to do anything. We just provide it with data and let it figure out what to do. Parents might relate to this.
There are three types of unsupervised learning techniques:
Clustering: As the name suggests, it is a learning method for identifying and grouping similar data points in larger datasets.
Dimensionality reduction: This is a technique for reducing the number of input variables in training data. When dealing with a lot of features (columns), it is often useful to reduce the dimensionality to retain more important features.
Association: This is where we discover relationships between variables in a dataset. It maps out the structure well.
KNN explained
Starting with K—Nearest Neighbors. As mentioned earlier, it is a supervised learning algorithm. It is mainly used for classification and regression tasks.
How does it work?
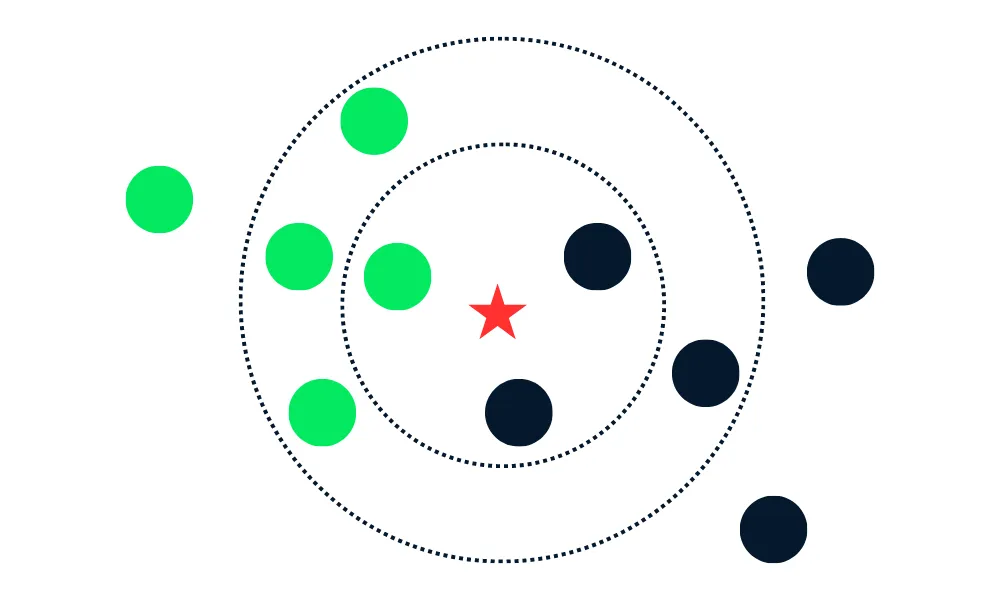
It works by finding the ‘k’ nearest data points to a given input point and deciding the output based on the majority vote (for classification) or average (for regression) of these ‘k’ nearest points.Note
It uses the entire dataset for training, making it a lazy learner and computationally expensive for larger datasets.
Source: https://medium.ealizadeh.com/
In the above case, for k = 3, two out of the three closest points were green, hence the new data point becomes green. For k = 5, three out of five were blue, so it becomes blue.
Theory always makes me sleepy, so let’s implement it and see it in action.
Let’s look at the dataset
I always take a second to appreciate the dataset first. Today we are playing around with Apple Quality Data; you will find it here.
This dataset contains information about various attributes of a set of fruits, providing insights into their characteristics.
It has the following important features:
Size
Weight
Sweetness
Crunchiness
Juiciness
Ripeness
Acidity
Quality
When was the last time you had an apple? Let me know in the comments below. I honestly prefer mango over all fruits.
The features are pretty self-explanatory. We can potentially use the dataset for fruit classification or quality prediction based on the features.
If you want to see the companion notebook with all the code and some cool visualizations, you can see it here.
Implementation
We start by importing the libraries and loading the dataset.
Also, note that I am primarily using Kaggle, but you can use your environment.
We then proceed to look at the data and do some preprocessing to help out the model.
We can visualize all the columns to see their distribution. For example, weight distribution looks like this:
We move on to splitting the data, training the model, and evaluating it.
This will train the model and test it as well. To evaluate this, we can create a confusion matrix to see how well the model did. This also shows the accuracy, precision, recall, and F1 score.
K means Clustering
Now that we have a decent understanding of what KNN is, we can dive into what K means is. It is an unsupervised learning algorithm that is used for clustering tasks. It partitions the dataset into ‘k clusters’. It requires the number of clusters ‘k’ to be specified in advance. And it assumes clusters are spherical and evenly sized, which might not always be the case.
I am giving a high-level overview in this article, but if you are interested in learning more, please reach out to me, and I’ll make a detailed article discussing what K means.
Let’s see it in action.
We have already imported the libraries. We will now scale the data to ensure similarity between all features. We will then train the model and visualize how the clusters
It looks something like this. Since this is a 2D plot, we can barely see 4 colors. But we can plot an awesome 3d interactive plot which you will find in the notebook. You can zoom or pan and turn it around. It even gives information on each data point, so check that out. It looks like this.
Conclusion
Both models are interesting techniques. KNN is used for classification or regression, and K means is used for clustering. And you now have a good understanding of Supervised and Unsupervised learning techniques. If you have any doubts, please let me know in the comments.
This concludes the article. Thank you for reading!
Resources
Articles that I referred to while writing this.
E. Alizadeh, “What K is in KNN and K-Means” Mar. 21, 2022. https://ealizadeh.com/blog/knn-and-kmeans


